বৃহস্পতিবার, ২৫ এপ্রিল ২০২৪, ০৬:৫৫ অপরাহ্ন



ARL’s way of self-reliance are modular, in which strong reading is alongside other process, as well as the bot is enabling ARL decide which job is right for and this processes. At this time, RoMan is actually testing a couple various methods out-of distinguishing items regarding three dimensional detector analysis: UPenn’s strategy is strong-learning-built, while you are Carnegie Mellon is utilizing a technique named perception as a consequence of research, and therefore hinges on a very antique database off three dimensional designs. Effect as a result of research functions only when you know just and therefore stuff you are looking for ahead of time, however, knowledge is much quicker since you need just a single model each object. ARL try testing this type of ways to decide which is considered the most flexible and productive, letting them work with additionally and vie against each other.
Perception is one of the things that deep learning tends to excel at. “The computer vision community has made crazy progress using deep learning for this stuff,” says Maggie Wigness, a computer scientist at ARL. “We’ve had good success with some of these models that were trained in one environment generalizing to a new environment, and we intend to keep using deep learning for these sorts of tasks, because it’s the state of the art.”
ARL’s standard means you are going to combine numerous techniques in ways in which power their advantages. Such as, a notion system that uses deep-learning-mainly based eyes so you can classify surface can perhaps work near to an autonomous driving system considering a method titled inverse support reading, where design can also be quickly getting created otherwise discreet because of the observations away from people troops. Old-fashioned support understanding optimizes a simple solution centered on depending award characteristics, in fact it is commonly used when you find yourself not always sure just what max decisions works out. This might be less of an issue into Armed forces, that can basically think that really-instructed people might be nearby showing a robotic the right solution to do things. “Once we deploy this type of robots, anything can change right away,” Wigness claims. “Therefore we wished a technique where we could possess an excellent soldier intervene, and with just a few examples away from a person from the profession, we can improve the system when we you would like another behavior.” A-deep-learning strategy would need “even more data and go out,” she states.
It is far from just study-sparse troubles and timely adaptation one deep understanding struggles which have. There are even inquiries of robustness, explainability, and you may security. “This type of concerns commonly novel towards army,” states Stump, “but it is particularly important whenever we’re speaking of systems that need lethality.” Is obvious, ARL is not already taking care of life-threatening independent guns options, however the laboratory is helping to place the fresh foundation for autonomous options from the U.S. armed forces a great deal more generally, and therefore offered ways such as for example options can be used in the future.
The requirements of an intense system should be a giant the amount misaligned to the requirements away from an armed forces mission, that’s a problem.
Protection are a glaring concern, yet there isn’t a very clear technique for and make an intense-discovering system verifiably safe, according to Stump. “Starting strong understanding with cover limitations are a major look efforts. Once the latest goal change, or perhaps the perspective changes, it’s hard to deal with one to. It’s not also Sugarmomma a document matter; it’s a buildings question.” ARL’s standard architecture, whether it’s a perception component that makes use of strong learning otherwise an independent riding module that utilizes inverse reinforcement studying or something more, can develop areas of a bigger autonomous system one to incorporates the new types of coverage and you can adaptability the armed forces means. Most other modules about system is also operate at a higher level, playing with additional processes which might be far more proven or explainable and that can be step in to safeguard the overall system away from bad unpredictable behavior. “When the additional information is available in and change that which we must perform, you will find a ladder indeed there,” Stump states. “It all happens in a rational means.”

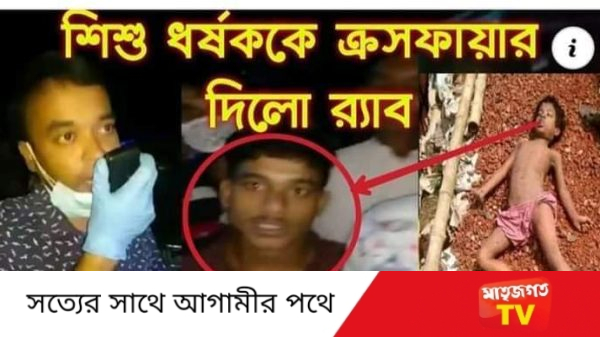

















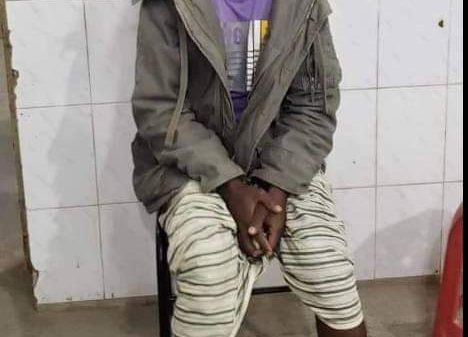












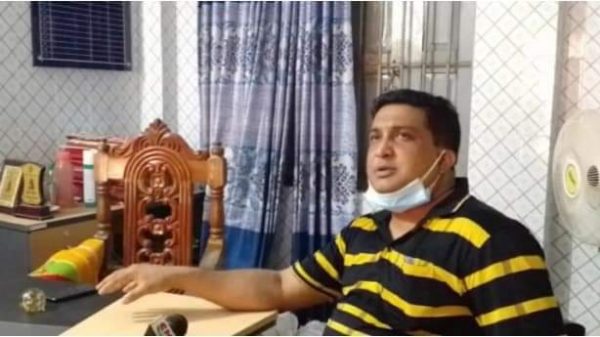





















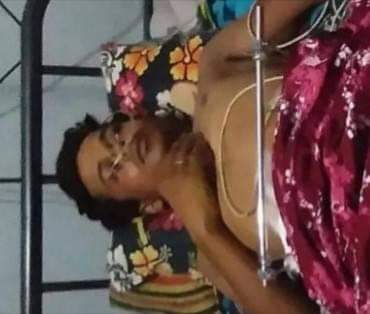



































































































































































































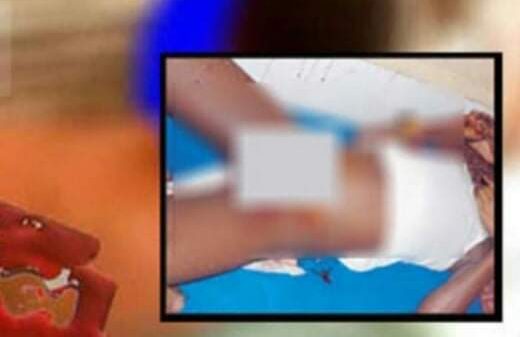

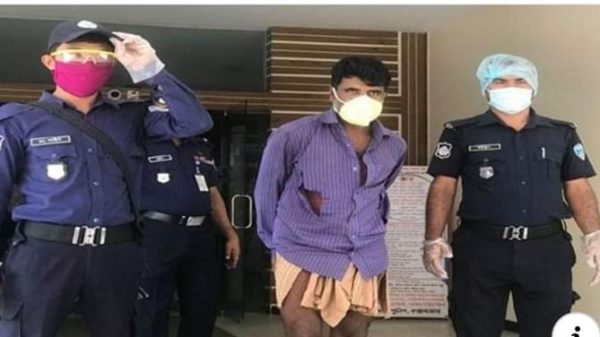






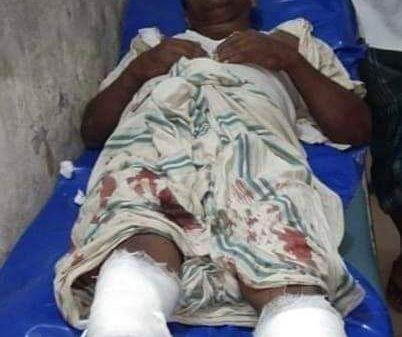













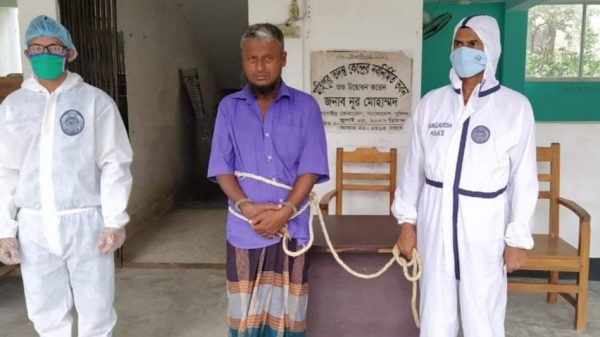


















































Leave a Reply